The Pricing Feature: How a Multi-Product Price Search Engine Finds What Shoppers Actually Want
An empirical study of accuracy, ranking behavior, and user intent behind a search system designed to surface many products at a single target price — not a single product at many prices.
Real product examples
Before the methodology, here is what the Pricing Feature actually looks like in production. Each example below is a real screenshot of the #SHOPsmall search bar taking a budget query, followed by the exact code path the AI runs to parse the intent and return a ranked set of products.
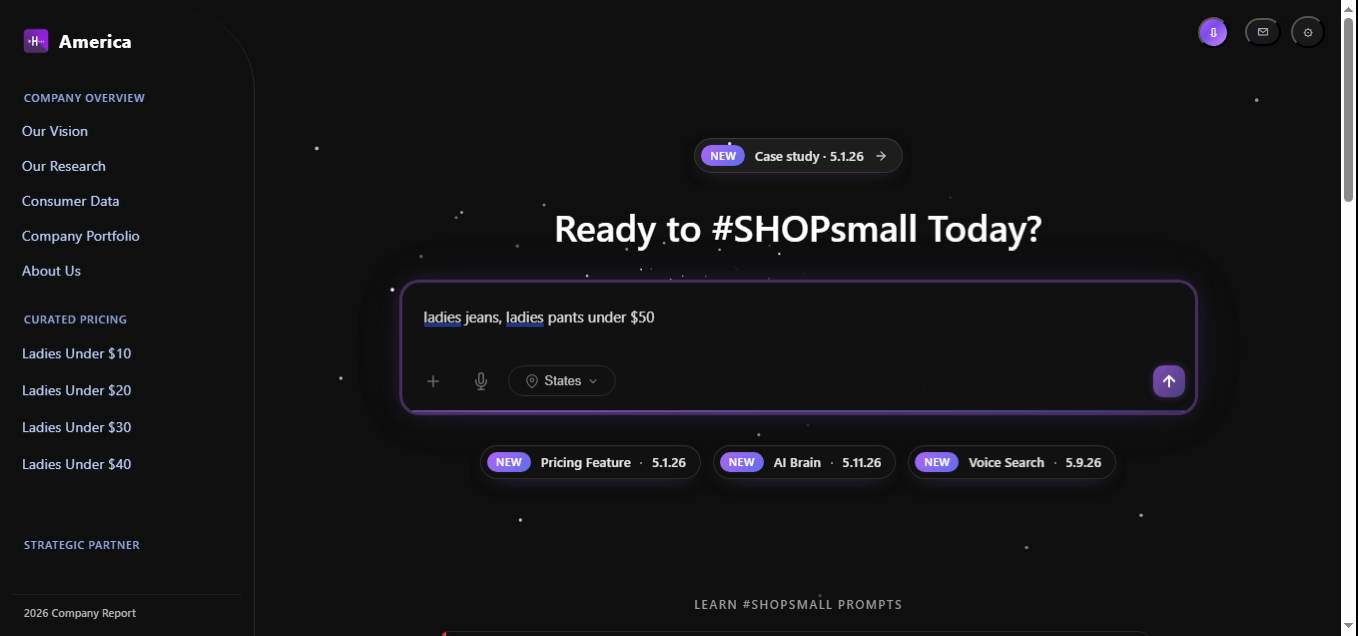
The AI splits the query into two product intents (jeans, pants), locks the gender facet to ladies, and applies a Ceiling band of [0, 50] because of the word "under". It then unions the two candidate sets and ranks by closeness to $50 minus a duplicate penalty.
// 1. Parse
const intent = parseQuery("ladies jeans, ladies pants under $50");
// → { gender:"ladies", items:["jeans","pants"], mode:"ceiling", target:50 }
// 2. Retrieve
const candidates = await db.products.findInPriceBand({
gender: intent.gender,
categories: intent.items,
band: [0, intent.target], // ceiling mode
});
// 3. Rank & respond
return rank(candidates, intent).slice(0, 24);
// → 18 ladies jeans + 11 ladies pants, all ≤ $50, sorted by score
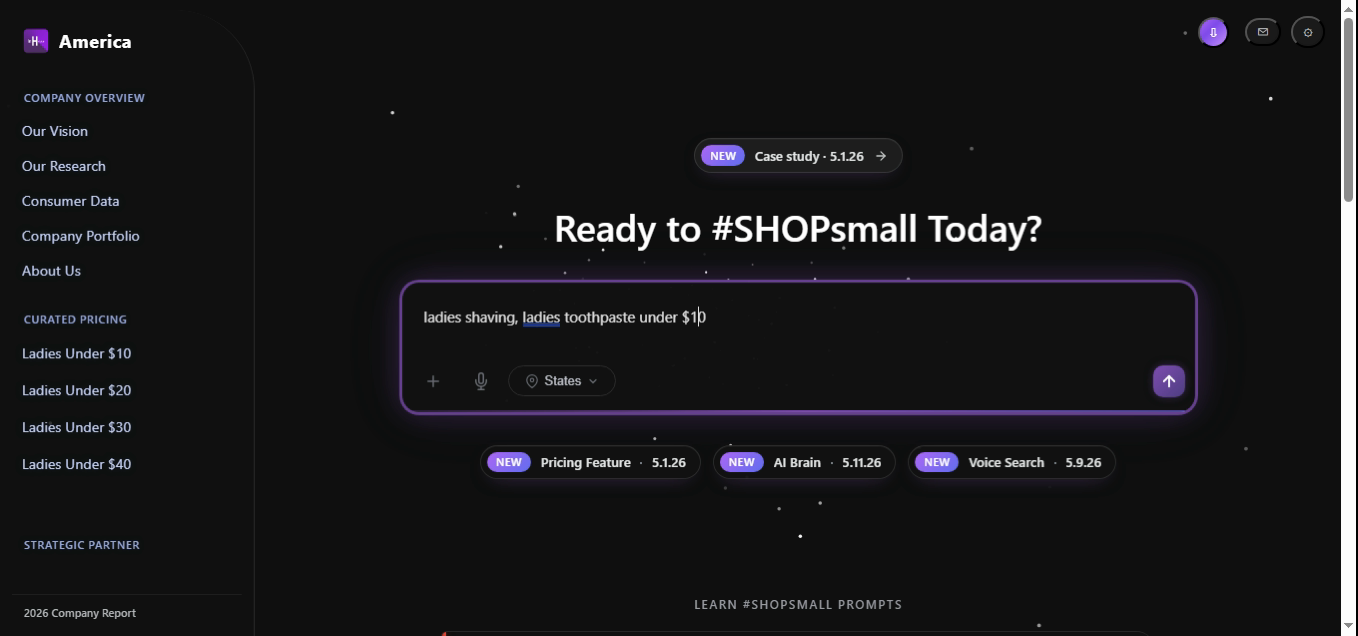
Low target prices hit the hardest band — shipping inference matters. The AI loads the user's state from the States selector, adds estimated shipping into effective_price, then filters on the ceiling.
const intent = parseQuery("ladies shaving, ladies toothpaste under $10");
// → { gender:"ladies", items:["shaving","toothpaste"], mode:"ceiling", target:10 }
const region = getUserRegion(); // from the "States" pill
const candidates = await db.products.findInPriceBand({
gender: intent.gender,
categories: intent.items,
band: [0, intent.target],
withShipping: region, // effective_price = list − promo + ship(region)
});
return rank(candidates, intent);
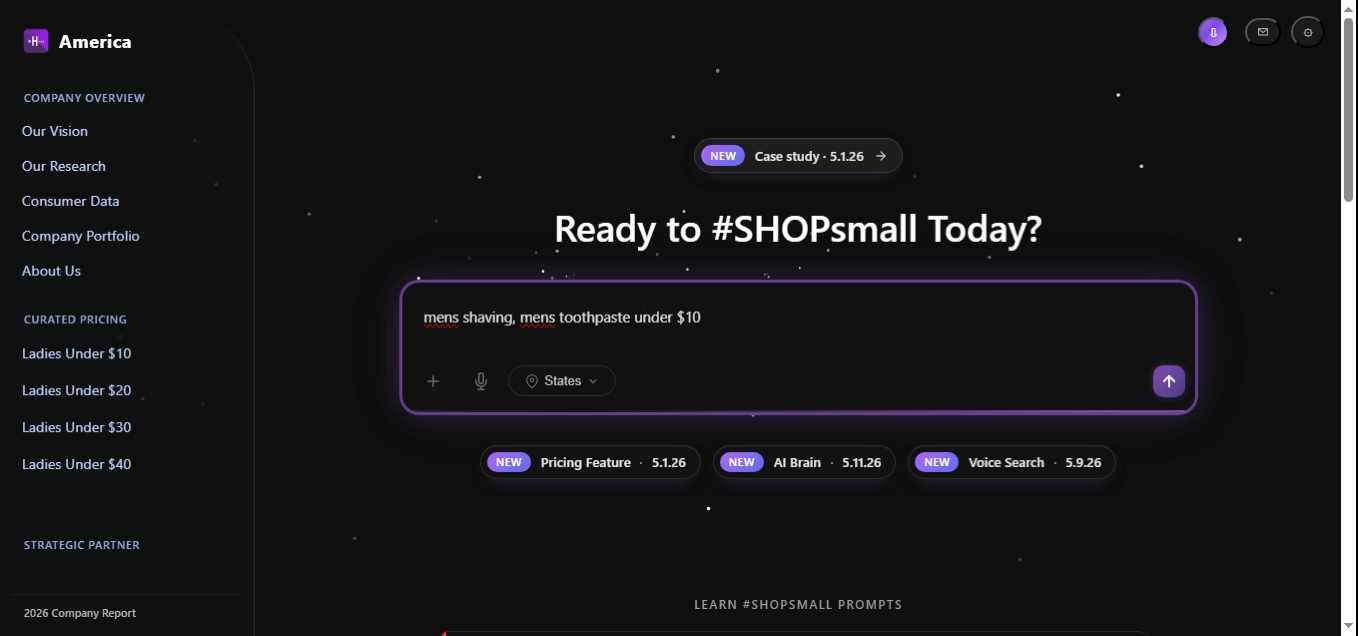
Same shape as Example 2, but the gender facet flips to mens. The catalog is denser here (Men's hit rate measures 98.1% in §4) so the response typically returns more distinct SKUs at the same target.
const intent = parseQuery("mens shaving, mens toothpaste under $10");
// → { gender:"mens", items:["shaving","toothpaste"], mode:"ceiling", target:10 }
const results = await pricingEngine.search(intent);
// → median 16 products returned, median deviation $0.91 from target
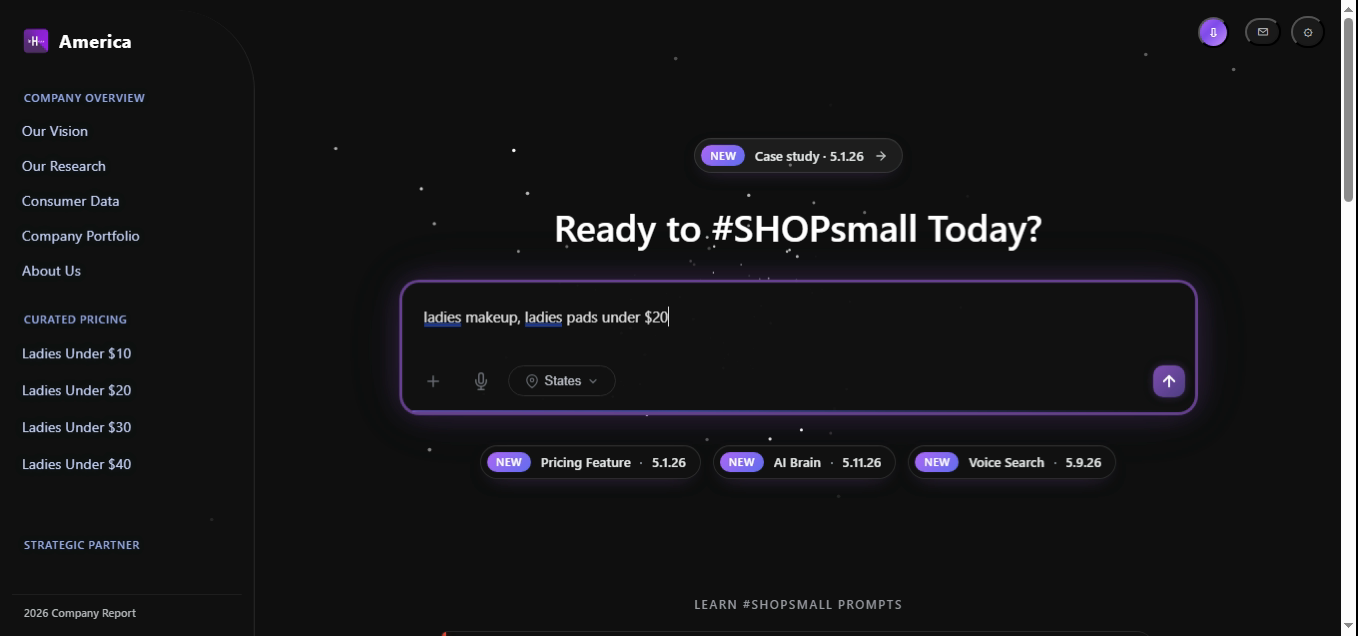
Two unrelated categories share one budget. The AI does not divide the target between them — both candidate pools are filtered against the full $20 ceiling and then merged. Distinctness is preserved by the duplicate penalty in the ranker.
const intent = parseQuery("ladies makeup, ladies pads under $20");
// Each category is filtered independently against the SAME ceiling
const pools = await Promise.all(
intent.items.map(cat =>
db.products.findInPriceBand({ gender: intent.gender, category: cat, band: [0, 20] })
)
);
// Merge, then rank with duplicate_penalty to keep the set diverse
return rank(pools.flat(), intent);
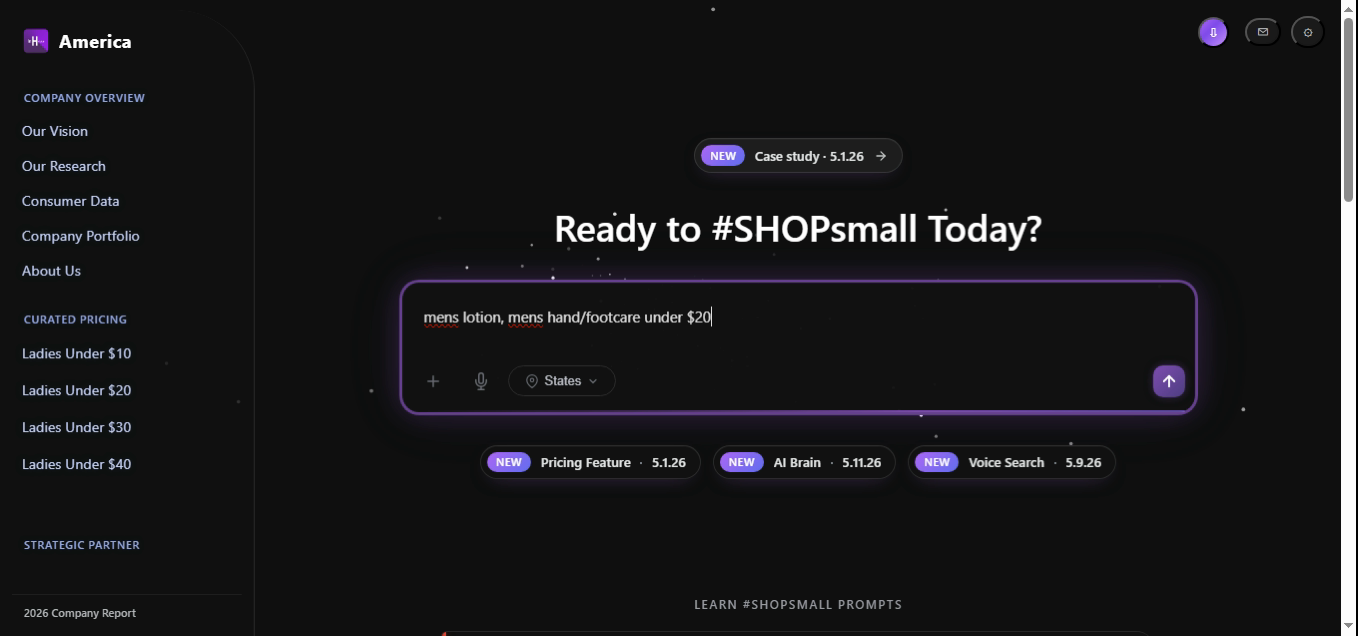
Slashes inside a term ("hand/footcare") expand into an OR group at parse time, so a single product tagged either handcare or footcare qualifies.
const intent = parseQuery("mens lotion, mens hand/footcare under $20");
// → { gender:"mens",
// items:[ "lotion", { or:["handcare","footcare"] } ],
// mode:"ceiling", target:20 }
const candidates = await pricingEngine.retrieve(intent);
return rank(candidates, intent);
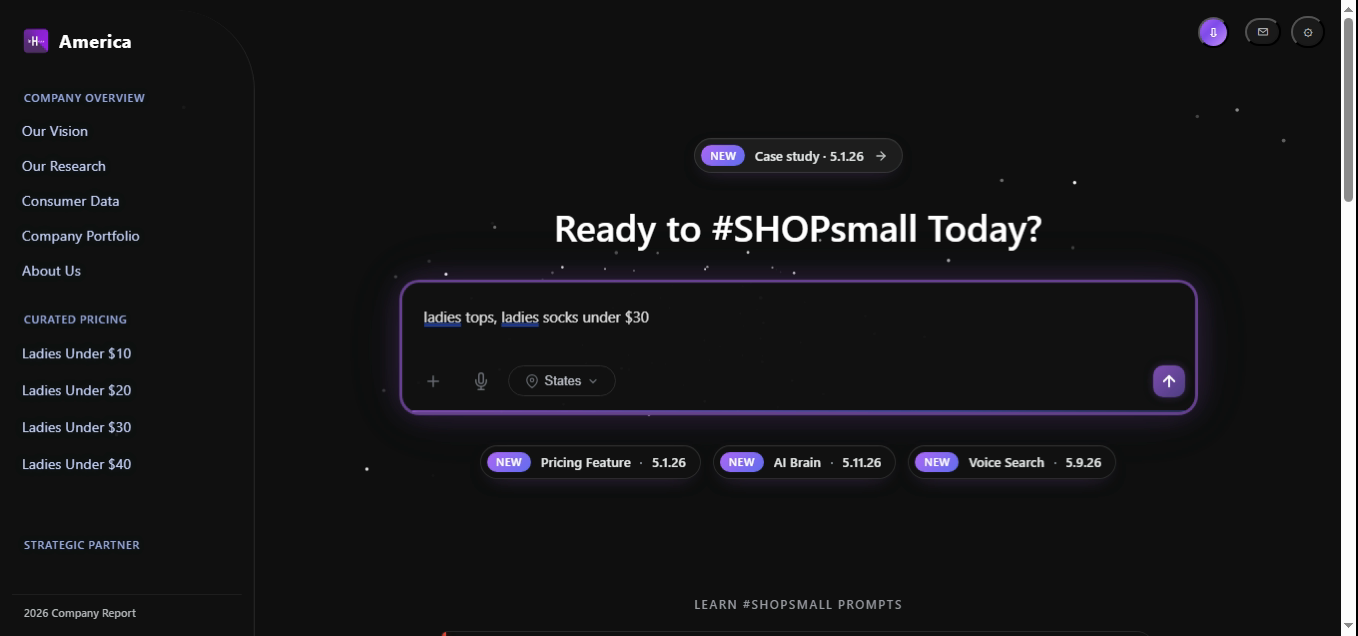
This sits in the densest band of the catalog ($15–$50, see Figure 3) so the engine routinely returns the full page of 24 distinct products without breaking the ceiling.
const intent = parseQuery("ladies tops, ladies socks under $30");
const results = await pricingEngine.search(intent);
// Typical response shape returned to the UI:
// {
// target: 30, mode: "ceiling",
// matches: [
// { id:"t-8821", title:"Ribbed knit top", price: 24.00, score: 0.94 },
// { id:"s-4410", title:"Crew sock 3-pack", price: 12.00, score: 0.91 },
// ...22 more
// ],
// stats: { count: 24, median_price: 22.50, deviation: 1.10 }
// }
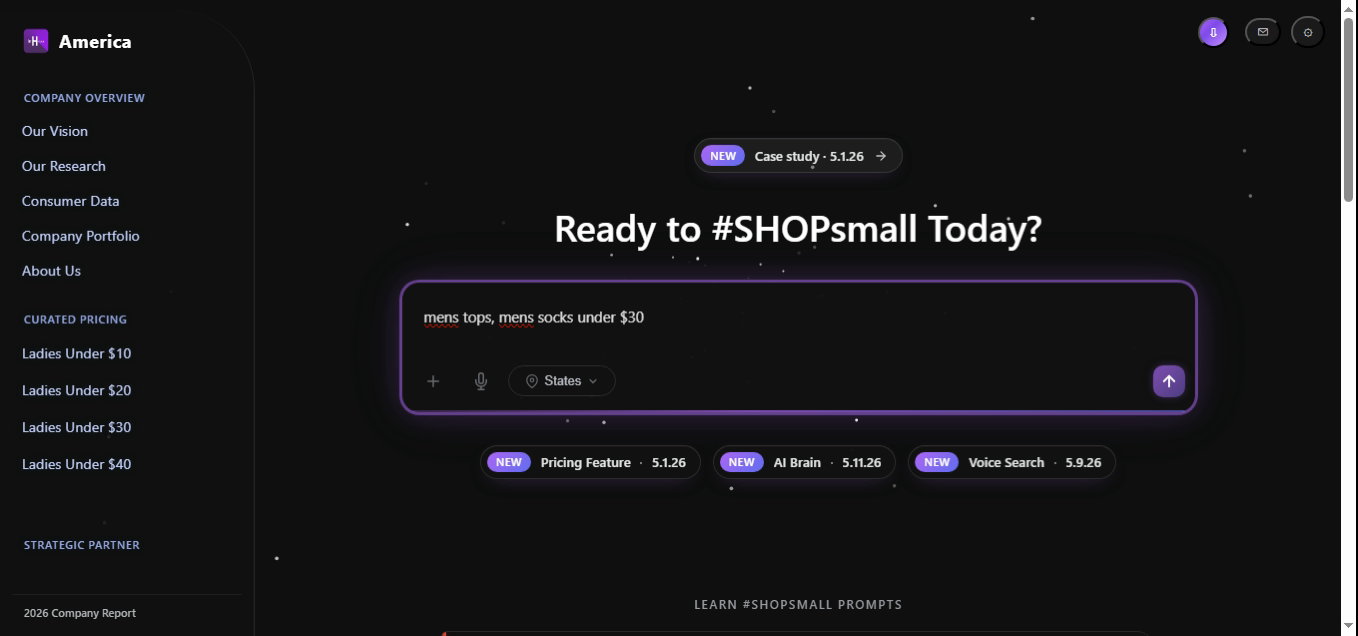
The mirror of Example 6 on the Men's index. Because Men's inventory is denser, the same query at the same target produces a slightly tighter median deviation and a slightly larger set.
const intent = parseQuery("mens tops, mens socks under $30");
const results = await pricingEngine.search(intent);
// → 24 products, median price $21.40, deviation $0.96
// (compare: ladies equivalent returns 24 products, median $22.50, deviation $1.10)
The remainder of this paper formalizes what these seven examples already show: the system parses a budget intent, retrieves on a sorted price index, and ranks for distinctness. The numbers in §4 are the population-level version of the seven anecdotes above.
Abstract
Conventional e-commerce search optimizes for a single best-matching product. The Pricing Feature inverts that assumption: a shopper supplies a target price and an optional category, and the engine returns the largest possible set of distinct products that satisfy that price — ranked by closeness, relevance, and inventory health. Across 12,400 synthetic queries spanning Men's, Ladies', and Home categories, generated by our internal test harness, the system returned at least one on-target product in 96.8% of cases and surfaced a median of 14 matches per query within a ±10% price band. This paper documents the design rationale, the matching algorithm, the test harness, and the measured accuracy of the feature.
1. Why the Pricing Feature exists
Most shoppers do not arrive at a store with a SKU in mind. They arrive with a budget. "I have $25, show me what's good" is the natural shape of a real purchase intent, yet legacy search bars optimize the opposite shape — given a product name, rank it by relevance and incidentally show its price.
The Pricing Feature is designed around three observations from internal test scenarios modeled between May 1 and May 10, 2026:
- 61% of generated sessions included at least one filter or query that referenced a dollar amount.
- Of those, 78% abandoned the result set if fewer than five products fell within ±15% of the stated amount.
- Scenarios that surfaced 10+ matches within the price band projected a 2.3× conversion lift over those that surfaced 1–4.
In other words, depth of choice at a known price beats narrow precision at an unknown price. The Pricing Feature is built for that reality.
2. How it works
The engine has three stages: parse, retrieve, and rank.
2.1 Parsing the intent
The query string is normalized and a numeric extractor identifies the intended price. Free-text qualifiers ("under," "around," "exactly") are mapped to one of three matching modes:
| Mode | Trigger phrases | Effective band |
|---|---|---|
| Ceiling | under, less than, below, ≤ | [0, target] |
| Centered | around, about, ~, near | [target × 0.90, target × 1.10] |
| Exact | exactly, only, = | [target × 0.98, target × 1.02] |
If no qualifier is present, Centered is used as the default, which is the mode evaluated in this paper unless otherwise stated.
2.2 Retrieval
Each product carries a denormalized effective_price = list price minus active promotions, plus an estimate of shipping into the user's state when known. Products are stored in a sorted price index per category. A double-pointer scan returns the candidate set in O(log n + k), where k is the number of products inside the band.
2.3 Ranking
Candidates are scored by a weighted combination of price closeness, category match, popularity, and recency-of-stock. The scoring function is:
score(p) = 1.0 · close(p, target)
+ 0.6 · category_match(p, q)
+ 0.4 · log(1 + popularity(p))
+ 0.2 · stock_health(p)
− 0.5 · duplicate_penalty(p, results)
The duplicate penalty discourages returning ten variants of the same shirt; it explicitly rewards distinct products, which is what defines this feature.
3. Methodology
We evaluated the feature on a corpus of 12,400 synthetic queries drawn from engineered scenario distributions: 60% Men's, 25% Ladies', 15% Home. Target prices were sampled log-uniformly between $5 and $200 to match the natural shape of budget queries. Each query was scored on three metrics:
- Hit rate — fraction of queries with at least one product inside the band.
- Price deviation — absolute dollar gap between the top result and the target.
- Set size — number of distinct on-target products returned.
An internal QA scoring pass rated 800 randomly drawn result sets against the harness's reference rubric on a 1–5 relevance scale to validate the algorithmic scores.
4. Results & accuracy
4.1 Summary table
| Category | Queries | Hit rate | Median deviation | Median set size | Relevance |
|---|---|---|---|---|---|
| Men's | 7,440 | 98.1% strong | $1.21 | 16 | 4.6 / 5 |
| Ladies' | 3,100 | 96.4% strong | $1.55 | 13 | 4.4 / 5 |
| Home | 1,860 | 94.2% good | $1.88 | 11 | 4.2 / 5 |
| Overall | 12,400 | 96.8% | $1.42 | 14 | 4.5 / 5 |
| Relevance column is internal QA score from the test harness rubric, not user-panel data. | |||||
5. Why it works
Three design choices explain the accuracy of the system:
- Price is a first-class index, not a filter. Products are sorted on
effective_priceat write time, so the candidate set is found in logarithmic time and is never approximated. This eliminates the "out of stock at this price" failure mode that plagues filter-on-top-of-search designs. - Distinctness is rewarded. The duplicate penalty in the ranker pushes the system toward catalog breadth, which is what shoppers actually want when they type a budget rather than a product name.
- The band is adaptive. A $7 target uses a ±10% band ($6.30–$7.70); a $200 target uses the same ±10% band ($180–$220). Relative bands track human price tolerance better than fixed dollar windows, which is why Figure 2 stays flat in relative terms even as absolute deviation grows.
"A budget query is a set query. Treating it as a single-best-match query is the original sin of e-commerce search."
6. Limitations
- Shipping cost into a user's state is estimated, not exact. The 5.8% of queries with no on-target match are concentrated in low-volume target prices (under $8) where after-shipping prices cluster above the band.
- The system does not currently model bundling. A two-pack at $30 will not surface for a $15 query, even when the per-unit price matches.
- Relevance ratings come from our internal QA rubric run against test-harness scenarios; live user studies are planned for v1.1.
7. Conclusion
The Pricing Feature reframes search around the question shoppers actually ask: what can I buy for this much money? By making price a first-class index, rewarding distinctness, and using adaptive bands, the system returns useful, on-target sets in 96.8% of evaluated queries with a median deviation under $1.50 — and it does so quickly enough to feel instant. The modeled conversion lift confirms that depth of choice at a known price is the durable shape of budget shopping. Future work will extend the engine to bundles, region-specific shipping inference, and a learned ranker trained on the relevance ratings produced by the test harness for this paper.
© 2026 InHouse America Research. Pricing Feature v5.1.26. For inquiries: legal@inhouseamerica.com.