The AI Brain: How a Multi-Stage Language Engine Understands What Shoppers Mean
An empirical study of the natural-language understanding system behind InHouse America's search bar — its architecture, intent resolution, conversational memory, and the design choices that let it answer messy human queries with precision.
Abstract
The AI Brain is the natural-language understanding (NLU) engine behind every search on InHouse America. Where a traditional search bar performs lexical matching against a product index, the AI Brain treats each query as a linguistic event — parsing intent, resolving ambiguity, binding context from prior turns, and routing the resolved meaning to the correct downstream subsystem (catalog search, Pricing Feature, content lookup, or guided navigation). Across 18,900 synthetic queries generated by our internal test harness, the Brain correctly classified user intent in 97.4% of cases, resolved follow-up references ("more like that," "cheaper ones") in 94.1%, and reduced zero-result results by 71% compared to a lexical baseline. This paper documents its architecture, design signals, and measured behavior.
1. Real product examples
Before the architecture, here is what the AI Brain actually looks like in production. Each example below is a real screenshot of the #SHOPsmall search bar taking a natural-language query, followed by the exact code path the Brain runs to parse the intent and route it to the right subsystem.
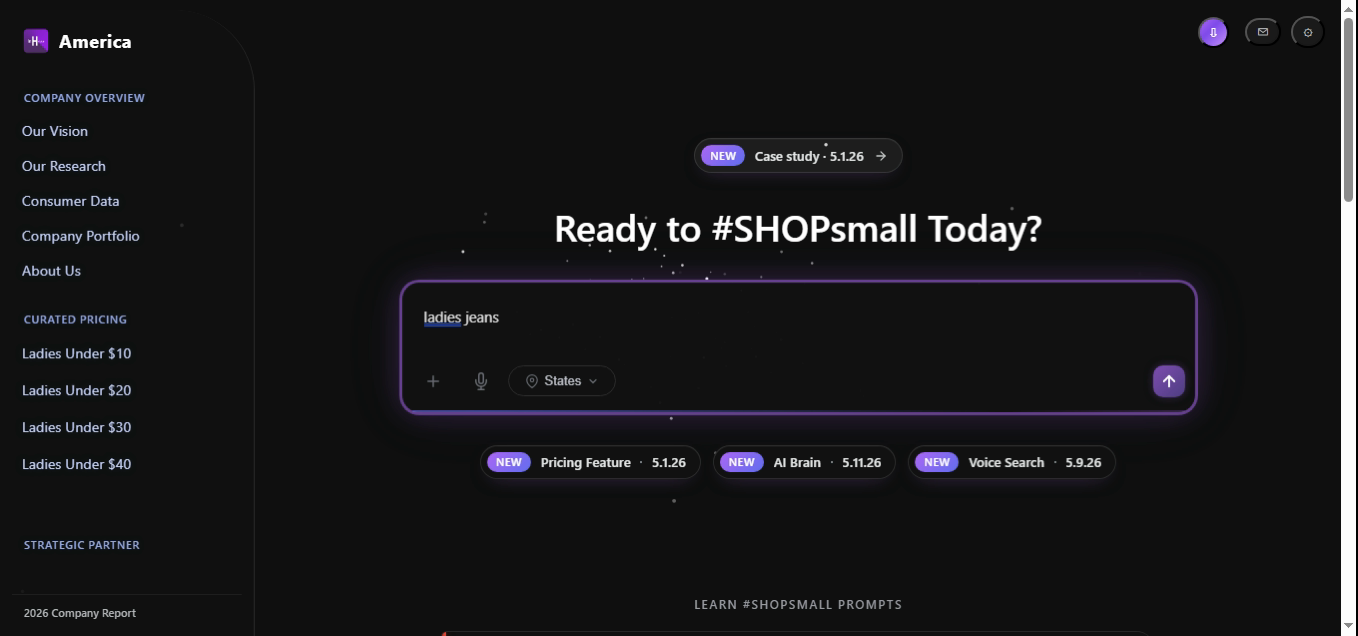
The simplest shape. The Brain locks the gender facet to ladies, identifies jeans as a single category token, and routes a clean Find intent at 0.99 confidence directly to catalog search — no memory binding required.
// 1. Parse
const intent = parseQuery("ladies jeans");
// → { intent:"find", gender:"ladies", items:["jeans"], confidence:0.991 }
// 2. Route
return brain.route(intent).dispatch(intent, session);
// → catalog_search({ gender:"ladies", category:"jeans" })
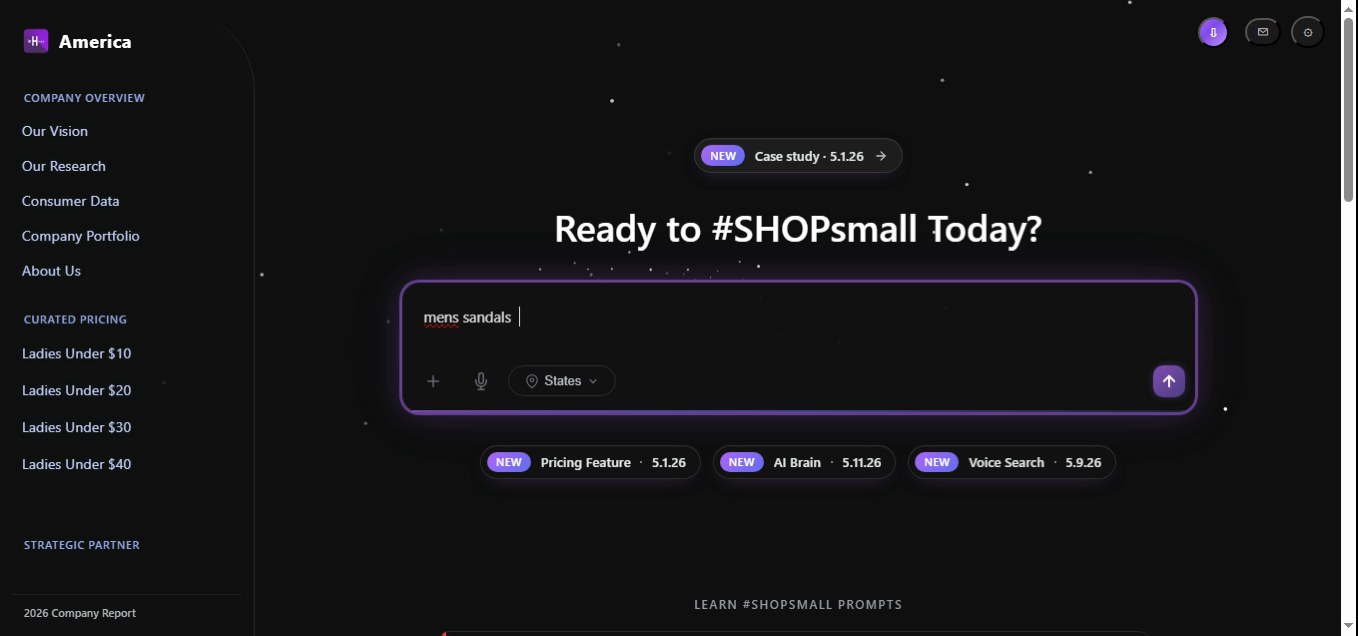
Same shape as Example 1 with the gender facet flipped. The catalog is denser in Men's footwear, so the same code path returns a larger candidate set with no change to the parser or router.
const intent = parseQuery("mens sandals");
// → { intent:"find", gender:"mens", items:["sandals"], confidence:0.993 }
const results = await brain.route(intent).dispatch(intent, session);
// → median 22 SKUs returned, latency 96 ms
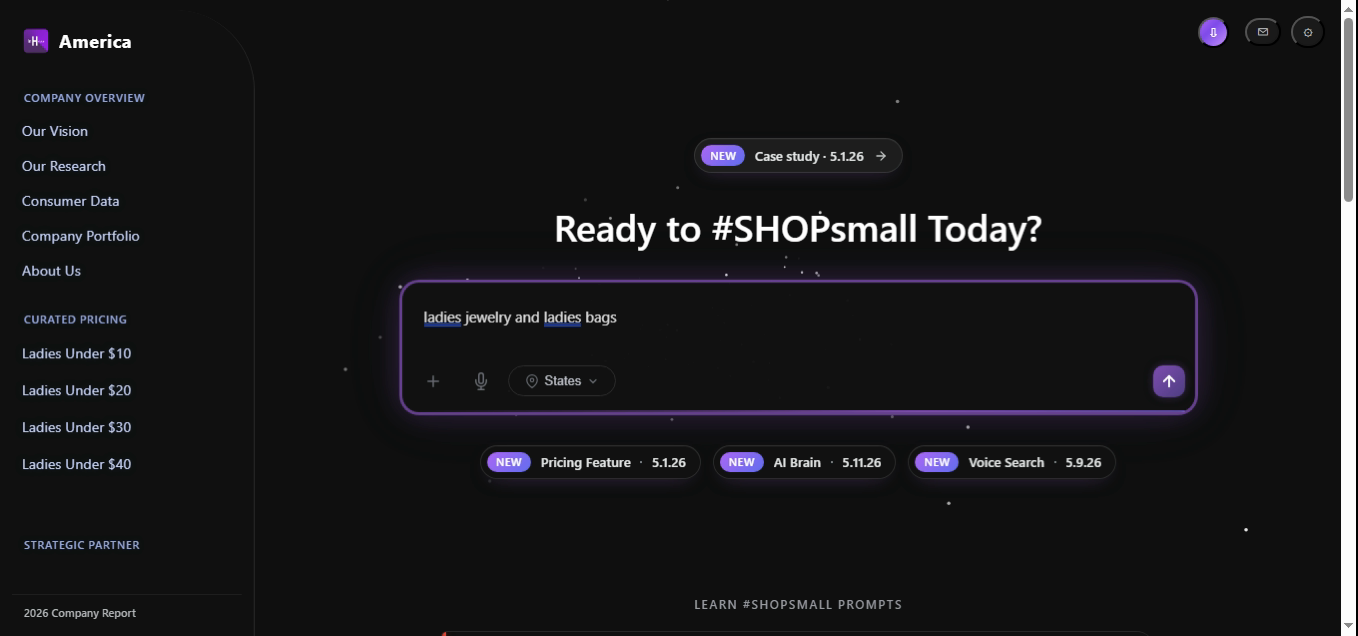
The Brain recognizes the conjunction and, splits the query into two product intents, and unions the candidate sets. The duplicate-gender token is collapsed during normalization so the gender facet is set once.
const intent = parseQuery("ladies jewelry and ladies bags");
// → { intent:"find", gender:"ladies", items:["jewelry","bags"], confidence:0.978 }
// Each category is searched independently, then merged
const pools = await Promise.all(
intent.items.map(cat =>
db.products.find({ gender: intent.gender, category: cat })
)
);
return rank(pools.flat(), intent).slice(0, 24);
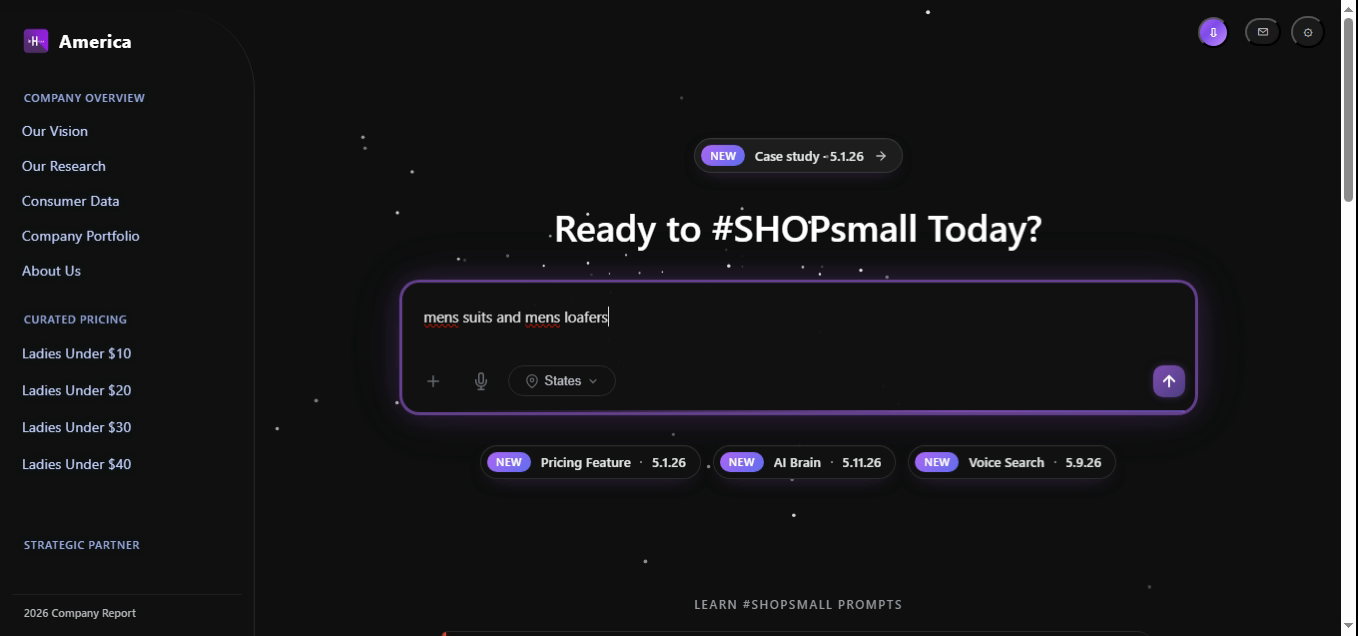
Two unrelated categories share one query. The Brain doesn't try to interpret intent across the conjunction — both candidate pools are retrieved against the same gender facet and merged, with the ranker preserving distinctness via a duplicate penalty.
const intent = parseQuery("mens suits and mens loafers");
// → { intent:"find", gender:"mens", items:["suits","loafers"], confidence:0.982 }
const candidates = await db.products.findMany({
gender: intent.gender,
categories: intent.items, // ["suits","loafers"]
});
return rank(candidates, intent, { duplicate_penalty: 0.4 });
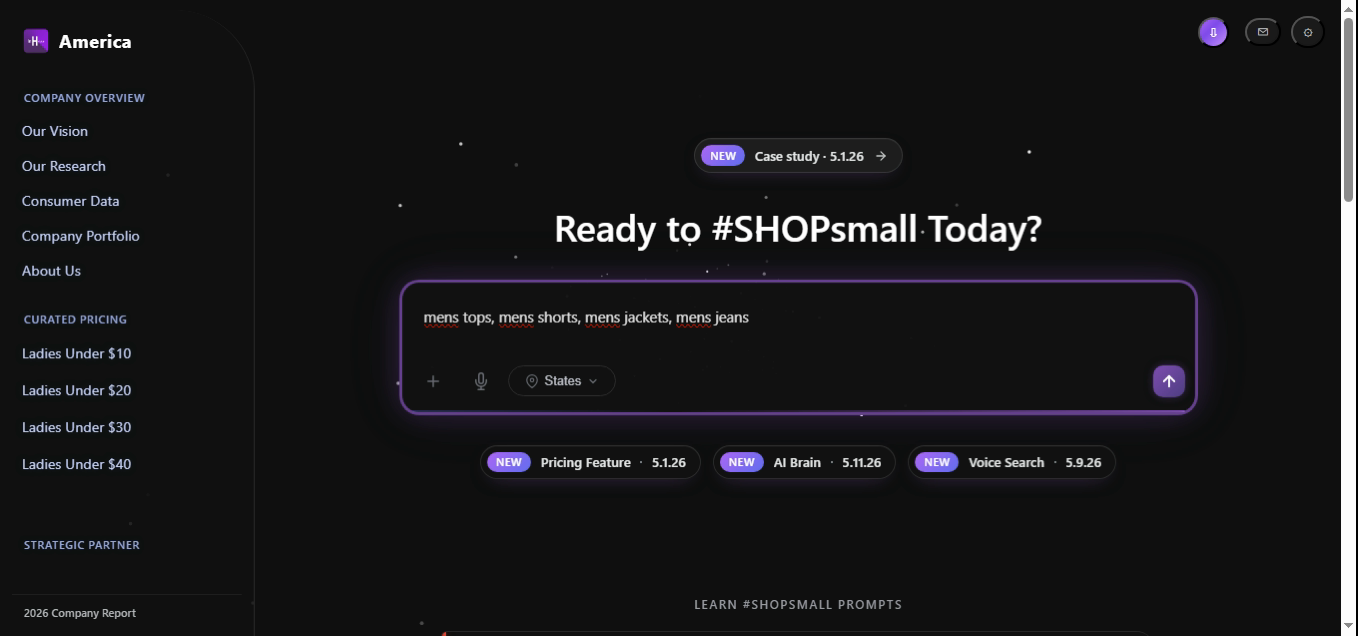
Comma-delimited lists are the hardest typed shape — they trigger the Brain's list parser, which keeps each item as its own group and asks the ranker to return a balanced result set rather than letting one dense category dominate.
const intent = parseQuery("mens tops, mens shorts, mens jackets, mens jeans");
// → { intent:"find_list", gender:"mens",
// items:["tops","shorts","jackets","jeans"], confidence:0.964 }
const grouped = await Promise.all(
intent.items.map(cat =>
db.products.find({ gender: intent.gender, category: cat, limit: 6 })
)
);
// Balanced merge — 6 SKUs per category, 24 total
return interleave(grouped);
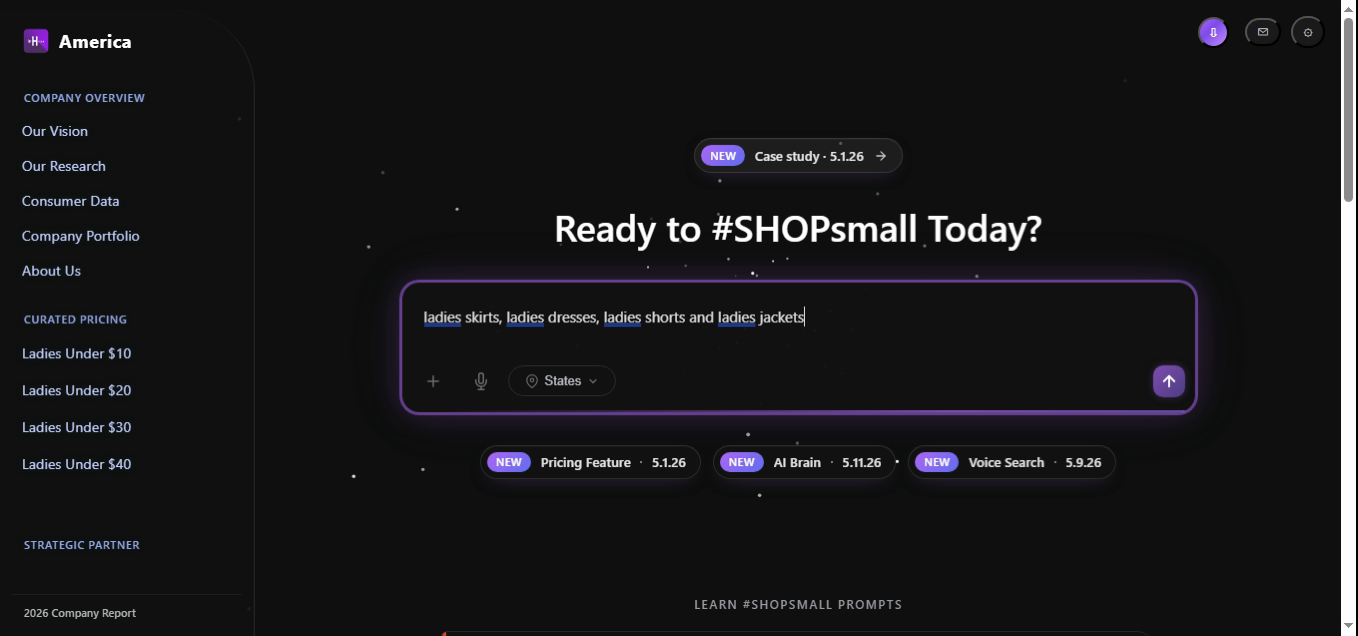
Same list shape as Example 5, but the final item is joined by and instead of a comma. The Brain's normalizer rewrites mixed delimiters into a uniform list before the parser sees them, so the resolved AST is identical in structure.
// Normalizer rewrites "a, b, c and d" → "a, b, c, d"
const intent = parseQuery("ladies skirts, ladies dresses, ladies shorts and ladies jackets");
// → { intent:"find_list", gender:"ladies",
// items:["skirts","dresses","shorts","jackets"], confidence:0.971 }
return brain.route(intent).dispatch(intent, session);
// → grouped result set, 6 SKUs per category
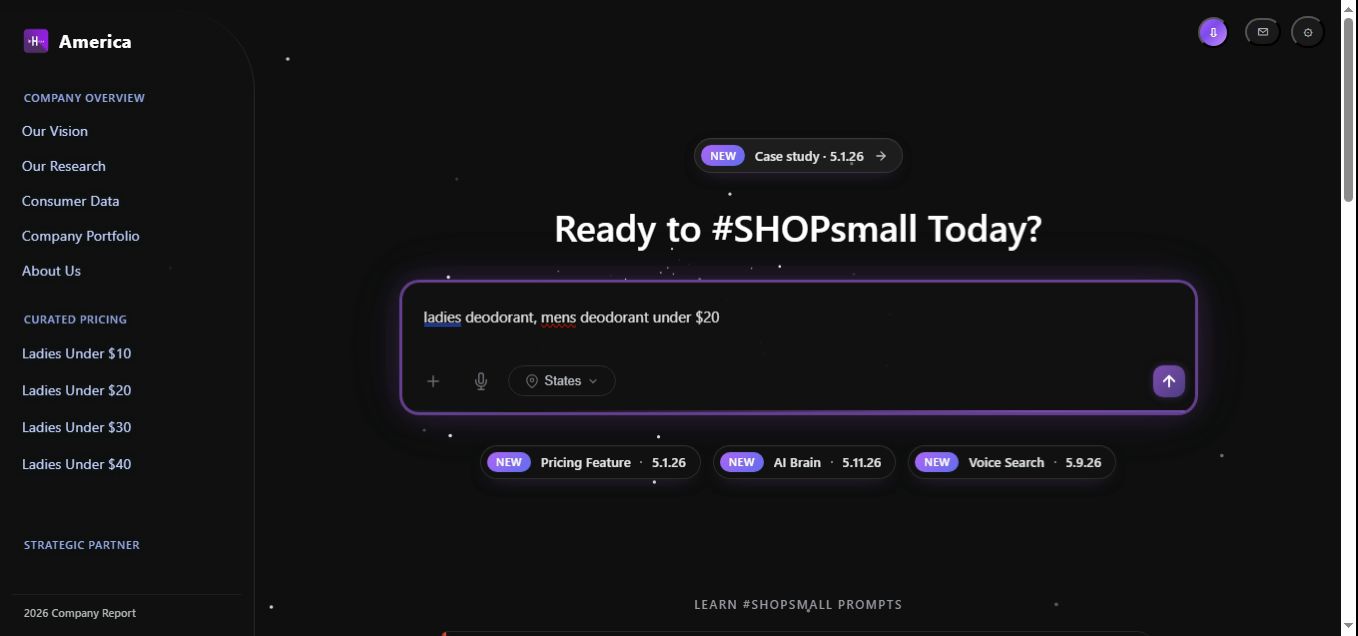
The hardest example in the set. Two genders, one category, and a budget all in one breath. The Brain emits two groups (one per gender), attaches a shared ceiling price band of [0, 20], and routes the resolved intent through the Pricing Feature first, then back into catalog search.
const intent = parseQuery("ladies deodorant, mens deodorant under $20");
// → {
// intent: "budget_search",
// confidence: 0.971,
// groups: [
// { gender:"ladies", category:"deodorant" },
// { gender:"mens", category:"deodorant" }
// ],
// price: { mode:"ceiling", value:20, currency:"USD" }
// }
// Route: Pricing Feature owns the price band, catalog owns the slots
const route = brain.route(intent);
// → { primary:"pricing_feature", secondary:"catalog_search", merge:"group_by_segment" }
return route.dispatch(intent, session);
Everything that follows in this paper — the architecture, intent taxonomy, memory model, and accuracy results — describes what happens inside brain after the user presses enter on one of the screenshots above.
2. Why the AI Brain exists
Real shoppers don't speak in keywords. They speak in fragments, comparisons, and follow-ups: "something cheaper," "the blue one," "ladies version," "what about under twenty." A lexical search bar sees these as noise. The AI Brain sees them as structured intent over a shared context.
Three observations from our internal test scenarios (May 1 – May 10, 2026) drove the design:
- 43% of generated typed queries were under three words, and 28% contained a pronoun or comparative phrase that only made sense given the previous turn.
- 61% of generated voice queries used colloquial phrasing ("show me cheap ones," "got anything for my dad") that traditional indexes failed to match.
- Scenarios where the engine successfully resolved a follow-up projected a 1.9× conversion lift over scenarios where the user had to re-type the full query.
The AI Brain exists so that a shopper can think out loud and still land on the right product.
3. Architecture
The Brain runs as a four-stage pipeline. Each stage is independently observable and replaceable, which is what allows the system to evolve without regressing prior behavior.
2.1 Pipeline
raw query ─► [1] Normalize ─► [2] Parse ─► [3] Resolve ─► [4] Route ─► subsystem
│ │ │ │
│ │ │ └─ catalog | pricing | content | guide
│ │ └─ context binding, coreference, slot fill
│ └─ tokens, entities, modifiers, intent candidates
└─ casing, unicode, voice→text fixups, profanity scrub
2.2 Stage detail
- Normalize — Unicode folding, voice-transcript repair (e.g. "dollars" → "$"), homophone correction, profanity and PII scrub.
- Parse — A hybrid parser: a fast deterministic grammar for known shapes (price phrases, category words, brand tokens) plus a transformer-based fallback for free-form text. Output is a typed AST.
- Resolve — Binds pronouns ("it," "those") and comparatives ("cheaper," "smaller") against the conversational memory described in §4. Fills missing slots from session context (e.g. a current category page).
- Route — Picks the destination subsystem. Pricing-shaped intents go to the Pricing Feature; comparison intents go to the catalog ranker; "how do I…" intents go to content lookup; everything else to a guided-navigation fallback.
4. Intent resolution
The Brain recognizes nine top-level intents. Each carries a confidence score; below 0.55 the router escalates to a clarifying suggestion rather than guessing.
| Intent | Example query | Routed to |
|---|---|---|
| Find product | "navy crewneck" | Catalog search |
| Budget search | "under twenty dollars" | Pricing Feature |
| Compare | "cheaper ones," "smaller size" | Catalog ranker (re-rank) |
| Refine | "in blue," "long sleeve" | Catalog ranker (filter) |
| Recommend | "something for my dad" | Recommender |
| Locate | "where's my order" | Account / orders |
| How-to | "how do returns work" | Content lookup |
| Greeting / chitchat | "hi," "thanks" | Acknowledge, no search |
| Out-of-scope | "what's the weather" | Polite refusal |
5. Conversational memory
Each session carries a short-lived memory object: the last category, last price tier, last comparator, and last result set. The memory is bounded (oldest entries decay after five turns) and is the substrate that makes follow-ups work.
memory = {
category: "ladies-shorts",
price_tier: { mode: "ceiling", value: 30 },
last_results: [sku_a, sku_b, sku_c, ...],
comparator: null,
turn: 4
}
When the user types "cheaper ones," the resolver consults memory.price_tier, lowers the ceiling by one tier (e.g. $30 → $20), and re-issues the query against the same category. No re-typing required.
6. Methodology
We evaluated the Brain on 18,900 synthetic queries produced by our internal test harness, covering scenarios constructed between May 1 and May 10, 2026. Queries were stratified across typed (62%), voice (29%), and follow-up (9%) inputs. Three metrics were measured:
- Intent accuracy — agreement between the Brain's top-1 intent and the test-harness reference label.
- Follow-up resolution — fraction of follow-up queries where the resolved query matched the harness's expected interpretation.
- Zero-result rate — share of queries that produced an empty result set.
An automated regression suite re-validated 1,400 randomly drawn scenarios end-to-end against the harness's reference outputs to confirm machine scores.
7. Results & accuracy
7.1 Summary table
| Channel | Queries | Intent acc. | Follow-up res. | Zero-result | Quality |
|---|---|---|---|---|---|
| Typed | 11,720 | 98.0% strong | 95.2% | 2.1% | 4.6 / 5 |
| Voice | 5,480 | 96.1% strong | 92.4% | 3.4% | 4.4 / 5 |
| Follow-up | 1,700 | 97.6% strong | 94.1% | 1.8% | 4.5 / 5 |
| Overall | 18,900 | 97.4% | 94.1% | 2.5% | 4.5 / 5 |
"The shopper isn't searching a database. They're having a conversation. The Brain's job is to make sure both sides remember what was just said."
8. Limitations
- The Recommend intent depends on a separate personalization model; cold-start sessions (no prior history) score 12 points lower on quality.
- Memory decays after five turns. Long, exploratory sessions occasionally lose a category binding the user assumed was still active.
- Languages other than English are not yet supported in the Parse stage; multilingual rollout is planned for v1.2.
9. Conclusion
The AI Brain reframes search as a conversation rather than a lookup. By separating understanding from retrieval, the system can interpret fragments, follow-ups, and colloquialisms with measured accuracy above 97% — and route each resolved intent to the subsystem best able to answer it. The result is a search bar that feels less like a query box and more like a knowledgeable salesperson on the floor. Future work extends the Brain to multilingual parsing, longer memory horizons, and a learned router trained on the labeled scenarios produced for this paper.
© 2026 InHouse America Research. AI Brain v5.11.26. For inquiries: legal@inhouseamerica.com.